


本文已经归档,不再更新,更多记录请访问:学习资料整理#Java
面试杂记
来之不易的美团面试,结果居然挂了...(附面试答案)
字节跳动面试官问我看过哪些源码,然后就没有然后了
关于技术总监面试被问细节的一个回答:
所以我的最终答案就是,“能力上不求全责备,意愿上不推三阻四”。如果面试遇到细节问题,最真诚的答案大概是这样:“我是技术总监,我可以把几个重要领域的细节全部谈清楚,但其它领域的细节我未必知道。不过我通常能判断一个不那么熟悉领域的方案是否靠谱,如果再多给我一点时间,我相信自己能答上来”。
高效维持长连接的关键在于
保活:处于连接状态时尽量不要断(进程保活、心跳保活)
断线重连:断了之后继续重连回来
注解
类继承关系中@Inherited的作用:
类继承关系中,子类会继承父类使用的注解中被@Inherited修饰的注解
接口继承关系中@Inherited的作用:
接口继承关系中,子接口不会继承父接口中的任何注解,不管父接口中使用的注解有没有被@Inherited修饰
类实现接口关系中@Inherited的作用:
类实现接口时不会继承任何接口中定义的注解
JSON 解析(Jackson)
最近fastjson安全问题频发,是时候彻底使用jackson了,有spring做背书,有保障。
三大核心模块
- Streaming流处理模块:定义底层处理流的API:JsonPaser和JsonGenerator等,并包含特定于json的实现。
com.fasterxml.jackson.core:jackson-core:2.10.1 - Annotations标准注解模块:包含标准的Jackson注解
com.fasterxml.jackson.core:jackson-annotations:2.10.1 - Databind数据绑定模块:在streaming包上实现数据绑定(和对象序列化)支持;它依赖于上面的两个模块,也是Jackson的高层API(如ObjectMapper)所在的模块
com.fasterxml.jackson.core:jackson-databind:2.10.1
java8支持
- 除了Java8的时间API外其它的API的支持,如Optional
com.fasterxml.jackson.datatype:jackson-datatype-jdk8:2.10.1 - 支持Java8新增的JSR310时间API
com.fasterxml.jackson.datatype:jackson-datatype-jsr310:2.10.1 - 此模块能够访问构造函数和方法参数的名称,从而允许省略@JsonProperty(当然前提是你必须加了编译参数:-parameters)
com.fasterxml.jackson.module:jackson-module-parameter-names:2.10.1
详细介绍可以参考:初识Jackson -- 世界上最好的JSON库
lombok 构建器 Builder
应将 @Builder”和“@AllArgsConstructor(access = AccessLevel.PRIVATE) 结合(默认的构造方法是default的)
@Builder
@AllArgsConstructor(access = AccessLevel.PRIVATE)
使用
@Accessors(chain = true)注解可以直接在 set 方法上形成链式调用。
如果使用@Builder的话切记所有私有全局变量都是需要显式赋值的,否则就是Null,不管你在原生T类中是否实例化,最终都是要被Builder的build()方法来重新实例化的。
如果使用了@Builder注解就不要使用其他@ConstructorArgs相关的注解,这从设计模式上是冲突的
同步容器/并发容器 所有操作一定线程安全吗?
我们可以在多线程场景中放心的使用单独这些方法,因为这些方法本身的确是线程安全的。
虽然同步容器的所有方法都加了锁,但是对这些容器的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。
同步容器是通过加锁实现线程安全的,并且只能保证单独的操作是线程安全的,无法保证复合操作的线程安全性。并且同步容器的读和写操作之间会互相阻塞。
并发容器是Java 5中提供的,主要用来代替同步容器。有更好的并发能力。而且其中的ConcurrentHashMap定义了线程安全的复合操作。
在多线程场景中,如果使用并发容器,一定要注意复合操作的线程安全问题。必要时候要主动加锁。
在并发场景中,建议直接使用java.util.concurent包中提供的容器类,如果需要复合操作时,建议使用有些容器自身提供的复合方法。
HashMap
JDK7 中 HashMap 采用的是位桶+链表的方式,即我们常说的散列链表的方式,而 JDK8 中采用的是位桶+链表/红黑树(有关红黑树请查看红黑树)的方式,也是非线程安全的。当某个位桶的链表的长度达到某个阀值的时候,这个链表就将转换成红黑树。
当链表长度超过阈值==8==时,将链表转换为红黑树,当删除到小于或等于==6==时重新变为链表,这样大大减少了查找时间。
链表和红黑树的转化是提高空间利用率(空间成本)和减少查询成本(时间成本)的折中,根据泊松分布,在负载因子默认为 0.75 的时候,单个 hash 槽内元素个数为 8 的概率小于百万分之一,所以将 7 作为一个分水岭,等于 7 的时候不转换,大于等于 8 的时候才进行转换成红黑树,小于等于 6 的时候就化为链表。
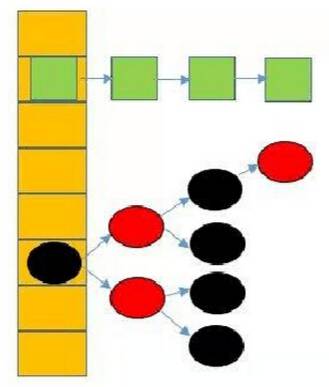
头插和尾插
新的 Entry 节点在插入链表的时候,Java8 之前是头插法,即新来的值会取代原有的值,原有的值就顺推到链表中去(原作者认为后来的值被查找的可能性更大一点,可以提升查找的效率)。但是,在 Java8 之后,都是使用尾部插入了。
这是因为使用头插会改变链表上元素的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环(环形依赖)的问题了。
HashMap是线程不安全的,其主要体现:
1.在jdk1.7中(头插法),在多线程环境下,扩容时会造成环形链或数据丢失。
2.在jdk1.8中(尾插法),在多线程环境下,会发生数据覆盖的情况。
一个普通的对象,能够作为HashMap的key么?
答案显然是可以的,但需要注意重写hashCode和equals方法。如果忘记重写的话,大概率会造成内存泄漏。
HashTable
Hashtable是不允许键或值为 null 的,HashMap的键值则都可以为 null。
这是因为Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。
如果你使用 null 值,就会使得其无法判断对应的 key 是不存在还是为空,因为你无法再调用一次 contain(key)来对 key 是否存在进行判断,ConcurrentHashMap同理。
HashTable VS HashMap
Hashtable是不允许键或值为 null 的,HashMap的键值则都可以为 null。- ==实现方式不同==:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
- ==初始化容量不同==:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- ==扩容机制不同==:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
所以,当其他线程改变了HashMap的结构,如:增加、删除元素,将会抛出ConcurrentModificationException异常,而Hashtable则不会
fail-fast 是什么
快速失败(fail—fast)是 java 集合中的一种机制,在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception,本质是检测到modCount!=expectedmodCount。
java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
安全失败(fail—safe)
java.util.concurrent(JUC)包下的容器都是安全失败的,可以在多线程下并发使用,并发修改。
ConcurrentHashMap
ConcurrentHashMap VS HashMap
与HashMap不同的是,ConcurrentHashMap并不允许key或者value为null。
ConcurrentHashMap VS HashTable
HashTable虽然性能上不如ConcurrentHashMap,但并不能完全被取代,两者的迭代器的一致性不同的,HashTable的迭代器是强一致性的,而ConcurrentHashMap是弱一致的。
ConcurrentHashMap的get,clear,iterator 都是弱一致性的。 Doug Lea 也将这个判断留给用户自己决定是否使用ConcurrentHashMap。
Jdk 1.7 和 Jdk 1.8 中底层实现区别
在 JDK8 中:ConcurrentHashMap 进行了巨大改动。它摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。它沿用了与它同时期的 HashMap 版本的思想,底层依然由数组+链表||红黑树的方式实现,但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。采用红黑树之后可以保证查询效率(O(logn)),甚至取消了ReentrantLock改为了synchronized。
- 在 jdk1.7 中是采用
Segment + HashEntry + ReentrantLock的方式进行实现的, - 而 1.8 中放弃了Segment臃肿的设计,取而代之的是采用
Node + CAS + Synchronized来保证并发安全进行实现。 - JDK1.8 的实现降低锁的粒度,JDK1.7 版本锁的粒度是基于Segment的,包含多个HashEntry,而 JDK1.8 锁的粒度就是
HashEntry(首节点) - JDK1.8 版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用
synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了 - JDK1.8 使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
可参考:ConcurrentHashMap总结
和 为什么ConcurrentHashMap的读操作不需要加锁?
、以及 JDK1.8中的HashMap实现
get 方法全程无锁
查看 get 操作源码时,会发现 get 操作全程是没有加任何锁的,这也是它比其他并发集合比如HashTable、用Collections.synchronizedMap()(synchronized(排斥锁mutex) {})包装的HashMap安全效率高的原因之一。
get 操作全程不需要加锁是因为
ConcurrentHashMap的Node的成员 val 和 next 是用volatile修饰的。与 Node 数组用 volatile 修饰没有关系。
锁升级: Jdk 1.8+ 的synchronized
以前我们都知道synchronized性能好,但是 Jdk 1.8 升级之后反而多了很多synchronized的使用,这是因为:使用了锁升级。
synchronized之前一直都是重量级的锁,但是后来 java 官方对他进行了升级,升级后采用的是锁升级的方式。
就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
所以是一步步升级上去的,最初也是通过很多轻量级的方式锁定的。
多线程
进程是拥有资源的基本单位, 线程是CPU调度的基本单位
线程池
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ExecutorsPoolController {
public static void main(String[] args) {
/**
* 创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
* 那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线
* 程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制
* ,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
*/
ExecutorService service = Executors.newCachedThreadPool();
/**
* 创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线
* 程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程
* 因为执行异常而结束,那么线程池会补充一个新线程。
*/
ExecutorService service1 = Executors.newFixedThreadPool(100);
/**
* 创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单
* 线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新
* 的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
*/
ExecutorService service2 = Executors.newSingleThreadExecutor();
/**
* 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
*/
ExecutorService service3 = Executors.newScheduledThreadPool(100);
/**
* ThreadPoolExecutor是JDK并发包提供的一个线程池服务,基于
* ThreadPoolExecutor可以很容易将一个Runnable接口的任务
* 放入线程池中。
*
* 1. 参数解释
* corePoolSize: 核心线程数,会一直存活,即使没有任务,线程池也会维护线程的最少数量
* maximumPoolSize: 线程池维护线程的最大数量
* keepAliveTime: 线程池维护线程所允许的空闲时间,当线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize。如果allowCoreThreadTimeout设置为true,则所有线程均会退出直到线程数量为0。
* unit: 线程池维护线程所允许的空闲时间的单位、可选参数值为:TimeUnit中的几个静态属性:NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS。
* workQueue: 线程池所使用的缓冲队列,常用的是:java.util.concurrent.ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue
* handler: 线程池中的数量大于maximumPoolSize,对拒绝任务的处理策略,默认值ThreadPoolExecutor.AbortPolicy()。
*/
ExecutorService service4 = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors(),100, 120L, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(1000));
Future<String> future = service4.submit(new Callable<String>() {
@Override
public String call() throws Exception {
// TODO Auto-generated method stub
return "我是线程,我是执行结果";
}
});
try {
System.out.println(future.get());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
service3.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println("我是线程");
}
});
/**
* submit execute
* submit会返回线程的执行结果
*/
}
}
线程池大小的选取
有两种简单的方法(N为CPU总核数),不建议生产环境使用:
- 如果是CPU密集型应用,则线程池大小设置为
N+1 - 如果是IO密集型应用,则线程池大小设置为
2N+1
线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
一般的有一个相对靠谱的公式来估算线程池大小:
最佳线程数目 = (线程等待时间/线程CPU时间 + 1)* CPU数目
优雅关闭线程池
threadPool.shutdown(); // Disable new tasks from being submitted
// 设定最大重试次数
try {
// 等待 60 s
if (!threadPool.awaitTermination(60, TimeUnit.SECONDS)) {
// 调用 shutdownNow 取消正在执行的任务
threadPool.shutdownNow();
// 再次等待 60 s,如果还未结束,可以再次尝试,或者直接放弃
if (!threadPool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("线程池任务未正常执行结束");
}
} catch (InterruptedException ie) {
// 重新调用 shutdownNow
threadPool.shutdownNow();
}
一个生产环境常用 JVM 参数
JAVA_OPTS="-server -Xms1g -Xmx1g -XX:PermSize=256m -XX:MaxPermSize=512m -Xss256K -XX:NewRatio=4 -XX:SurvivorRatio=1 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:CMSInitiatingOccupancyFraction=68 -XX:+UseParNewGC -XX:+DisableExplicitGC -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log -Dfile.encoding=utf-8 -Djava.awt.headless=true"
-server -Xms2g -Xmx2g -Dfile.encoding=utf-8 -Djava.awt.headless=true -XX:ParallelGCThreads=8 -XX:PermSize=256m -XX:MaxPermSize=512m -Xss256k -XX:-DisableExplicitGC -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Djdk.tls.ephemeralDHKeySize=2048
-Djdk.tls.ephemeralDHKeySize=2048 -server -Xms1024M -Xmx1024M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=512M -Dfile.encoding=utf-8 -Djava.awt.headless=true -XX:SurvivorRatio=1 -XX:MaxTenuringThreshold=4 -XX:TargetSurvivorRatio=60 -XX:NewRatio=4 -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseBiasedLocking -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCompressedOops -XX:+UseCMSCompactAtFullCollection -XX:+CMSScavengeBeforeRemark -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:+CMSClassUnloadingEnabled -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintClassHistogram -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:/logs/gc.log -Dfile.encoding=utf-8
【更新】生产环境 tomcat JVM 优化配置(tomcat8,jdk8)
1G的情况:
JAVA_OPTS="-server -Xms1g -Xmx1g -Xmn750m -Xss256k -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -Dfile.encoding=utf-8 -Djava.awt.headless=true"
2G的情况:
JAVA_OPTS="-server -Xms2g -Xmx2g -Xmn1g -Xss256k -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -Dfile.encoding=utf-8 -Djava.awt.headless=true"
4G的情况:
JAVA_OPTS="-server -Xms4g -Xmx4g -Xmn3g -Xss256k -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -Dfile.encoding=utf-8 -Djava.awt.headless=true"
6G的情况:
JAVA_OPTS="-server -Xms6g -Xmx6g -Xmn4g -Xss512k -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -Dfile.encoding=utf-8 -Djava.awt.headless=true"
附带一个 tomcat server.xml 优化(tomcat8):
<Service name="Catalina">标签下添加/修改
<Executor name="tomcatThreadPool"
namePrefix="catalina-exec-"
maxThreads="200"
minSpareThreads="20"
prestartminSpareThreads = "true"
maxQueueSize = "1000"
/>
<Connector port="保持原来的端口不变"
executor="tomcatThreadPool"
protocol="org.apache.coyote.http11.Http11NioProtocol"
enableLookups="false"
acceptorThreadCount="2"
acceptCount="1000"
connectionTimeout="20000"
redirectPort="8443" />
常见参数含义解读
-server: 以该模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升-Xms: 初始堆大小(默认值:物理内存的1/64(<1GB))
默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.
-Xmx: 最大堆大小(默认值:物理内存的1/4(<1GB))
默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
-Xmn: 年轻代大小(1.4or lator)
注意:此处的大小是(eden+ 2 survivor space)。与
jmap -heap中显示的New gen是不同的。
整个堆大小=年轻代大小 + 年老代大小 + 持久代大小.
增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-XX:PermSize: 设置持久代(perm gen)初始值(默认值:物理内存的1/64)-XX:MaxPermSize: 设置持久代最大值(默认值:物理内存的1/4)-Xss: 每个线程的堆栈大小-XX:NewRatio: 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)
-XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
-XX:SurvivorRatio: Eden区与Survivor区的大小比值
设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
-XX:+UseCompressedOops: 在JDK 1.6+版本默认开启,jvm开启了压缩之后 64 位系统的对象也只占用12byte。
new 一个空对象在 32 位系统中占用内存大小是 8byte(对象头,在堆中)+ 4byte(对象的引用地址,在栈中)= 12byte;
new 一个空对象在 64 为系统中占用内存大小是 16byte(对象头,在堆中)+ 8byte(对象的引用地址,在栈中)= 24byte;
可想而知同一个对象在 64 位系统中占的内存加大一半了,不仅消耗运行内存,而且 GC 回收时很耗CPU。
-XX:+UseConcMarkSweepGC: 使用CMS内存收集-XX:+UseCMSInitiatingOccupancyOnly: 使用手动定义初始化定义开始CMS收集(禁止hostspot自行触发CMS GC)-XX:+UseParNewGC: 设置年轻代为并行收集
可与CMS收集同时使用,JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值
-XX:+DisableExplicitGC: 关闭System.gc()。(这个参数需要严格的测试)-XX:+UseCMSInitiatingOccupancyOnly: 使用手动定义初始化定义开始CMS收集(禁止hostspot自行触发CMS GC)-XX:+CMSClassUnloadingEnabled: 表示在使用CMS垃圾回收机制的时候是否启用类卸载功能
默认这个是设置为不启用的,如果启用了,垃圾回收会清理持久代,移除不再使用的classes(前提是开启了CMS)
-XX:+CMSScavengeBeforeRemark: 开启在CMS重新标记阶段之前的清除尝试-XX:CMSInitiatingOccupancyFraction=68: 使用68%后开始CMS收集(默认值:92%)
为了保证不出现 promotion failed 错误,该值的设置需要满足公式
-XX:+PrintClassHistogram: 打印出实例的数量以及空间大小-XX:+PrintGCDetails: 打印GC时的内存,并且在程序结束时打印堆内存使用情况-XX:+PrintGCTimeStamps: 每次GC时会打印程序启动后至GC发生的时间戳-XX:+PrintHeapAtGC: 每次GC时会分别打印回收前与回收后堆信息-Xloggc:log/gc.log: 将GC日志输出到指定位置-verbose:class: 跟踪类的加载和卸载-Dfile.encoding: 设置系统文件编码格式-Djava.awt.headless=true: 一般用在 Java 处理图形应用时(Headless模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标等。)
分布式 VS 高并发 VS 多线程
水平扩展:当一台机器扛不住流量时,就通过添加机器的方式,将流量平分到所有服务器上,所有机器都可以提供相当的服务;
垂直拆分:前端有多种查询需求时,一台机器扛不住,可以将不同的需求分发到不同的机器上,比如A机器处理余票查询的请求,B机器处理支付的请求。
● 分布式是从物理资源的角度去将不同的机器组成一个整体对外服务,技术范围非常广且难度非常大,有了这个基础,高并发、高吞吐等系统很容易构建;
● 高并发是从业务角度去描述系统的能力,实现高并发的手段可以采用分布式,也可以采用诸如缓存、CDN等,当然也包括多线程;
● 多线程则聚焦于如何使用编程语言将CPU调度能力最大化。
阿里巴巴禁止在 foreach 循环里进行元素的 remove/add 操作
我们使用的增强for循环,其实是Java提供的语法糖,其实现原理是借助Iterator进行元素的遍历。
但是如果在遍历过程中,不通过Iterator,而是通过集合类自身的方法对集合进行添加/删除操作。那么在Iterator进行下一次的遍历时,经检测发现有一次集合的修改操作并未通过自身进行,那么可能是发生了并发被其他线程执行的,这时候就会抛出异常,来提示用户可能发生了并发修改,这就是所谓的 fail-fast 机制。
如果是JDK1.8+,没有并发访问的情况下,可以使用:
Collection.removeIf(Predicate<? super E> filter)方法删除,是代码更优雅。
另外上述说的抛出
ConcurrentModificationException主要是指ArrayList,如果使用CopyOnWriteArrayList集合(快照技术),则不会报错,不过也不建议使用 foreach 中直接删除。
还可参考:这道Java基础题真的有坑!我求求你,认真思考后再回答、这道Java基础题真的有坑!我也没想到还有续集
【结论来了】:
在单线程的情况下,只要你的ArrayList集合大小>=2(假设大小为n,即size=n),你删除倒数第二个元素的时候,cursor从0进行了n-1次的加一操作,size(即n)进行了一次减1的操作,所以n-1=n-1,即cursor=size。
因为判断条件返回为false,虽然你的modCount变化了。但是不会进入下次循环,就不会触发modCount和expectedModCount的检查,也就不会抛出ConcurrentModificationException.
正确 remove/add 姿势
- 1.直接使用普通 for 循环进行操作
普通 for 循环并没有用到 Iterator 的遍历,所以压根就没有进行 fail-fast 的检验。
其实存在一个问题,那就是 remove 操作会改变 List 中元素的下标,
可能存在漏删的情况。 - 2.直接使用 Iterator 进行操作
- 3.使用 Java 8 中提供的 filter 过滤
Java 8 中可以把集合转换成流,对于流有一种 filter 操作, 可以对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream。
- 4.使用增强 for 循环其实也可以
只要在删除之后,立刻结束循环体,不要再继续进行遍历就可以了,也就是说不让代码执行到下一次的 next 方法。
- 5.直接使用 fail-safe 的集合类
在 Java 中,除了一些普通的集合类以外,还有一些采用了 fail-safe (安全失败)机制的集合类。这样的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。
基于拷贝内容的优点是避免了ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。比如:
ConcurrentLinkedDeque
java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
Java Class文件编译的版本号与JDK版本号的对应关系
| JDK版本号 | Class版本号 | 16进制 |
|---|---|---|
| 1.1 | 45.0 | 00 00 00 2D |
| 1.2 | 46.0 | 00 00 00 2E |
| 1.3 | 47.0 | 00 00 00 2F |
| 1.4 | 48.0 | 00 00 00 30 |
| 1.5 | 49.0 | 00 00 00 31 |
| 1.6 | 50.0 | 00 00 00 32 |
| 1.7 | 51.0 | 00 00 00 33 |
| 1.8 | 52.0 | 00 00 00 34 |
JDK 版本号区别
官方对于奇数版本与偶数版本区别的解释: 从JDK版本7u71以后,JAVA将会在同一时间发布两个版本的JDK。
- 奇数版本:为BUG修正并全部通过检验的版本,官方强烈推荐使用这个版本。
- 偶数版本:包含了奇数版本所有的内容,以及未被验证的BUG修复,Oracle官方表示:除非你深受BUG困扰,否则不推荐您使用这个版本。
开源JDK
即便 Oracle 不再免费支持 Java 8 的更新,各个云厂商还是积极支持,站点为: https://adoptopenjdk.net/ ,可以让 Java 8 能继续保留非常长的时间。
线程上下文类加载器
线程上下文类加载器(context class loader)是从 JDK 1.2 开始引入的。类 java.lang.Thread中的方法 getContextClassLoader()和 setContextClassLoader(ClassLoader cl)用来获取和设置线程的上下文类加载器。如果没有通过 setContextClassLoader(ClassLoader cl)方法进行设置的话,线程将继承其父线程的上下文类加载器。Java 应用运行的初始线程的上下文类加载器是系统类加载器。在线程中运行的代码可以通过此类加载器来加载类和资源。
双亲委派模型并不能解决所有的类加载器问题,比如,Java 提供了很多服务提供者接口,允许第三方为这些接口提供实现。常见的 SPI 有 JDBC、JNDI、JAXP 等,这些 SPI 的接口由核心类库提供,却由第三方实现,这样就存在一个问题:
SPI 的接口是 Java 核心库的一部分,是由 BootstrapClassLoader 加载的;SPI 实现的 Java 类一般是由 AppClassLoader 来加载的。BootstrapClassLoader 是无法找到 SPI 的实现类的,因为它只加载 Java 的核心库。它也不能代理给 AppClassLoader,因为它是最顶层的类加载器。也就是说,双亲委派模型并不能解决这个问题。
线程上下文类加载器( ContextClassLoader)正好解决了这个问题。如果不做任何的设置,Java 应用的线程的上下文类加载器默认就是 AppClassLoader。在核心类库使用 SPI 接口时,传递的类加载器使用线程上下文类加载器,就可以成功的加载到 SPI 实现的类。
线程上下文类加载器在很多 SPI 的实现中都会用到。但在 JDBC 中,你可能会看到一种更直接的实现方式,比如,JDBC 驱动管理 java.sql.DriverManager 中的 loadInitialDrivers()方法中,你可以直接看到 JDK 是如何加载驱动的:
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
// 直接使用 AppClassLoader
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
getClassLoader() 和 getContextClassLoader() 的区别
- getClassLoader() 是当前类加载器,而 getContextClassLoader 是当前线程的类加载器
- getClassLoader 是使用双亲委派模型来加载类的,而 getContextClassLoader 就是为了==避开双亲委派==模型的加载方式的,也就是说它不是用这种方式来加载类
当前类加载器加载和定义当前方法所属的那个类。这个类加载器在你使用带单个参数的 Class.forName() 方法、Class.getResource() 方法和相似方法时会在运行时类的链接过程中被隐式调用(也就是说当你用Class.forname(package.className)的时候已经调用当前类加载器来加载这个类了)
Java 程序 CPU 分析、内存、IO、网络等分析
线上常见五种系统缓慢情况:
- FullGC 次数过多
- CPU 过高
- 不定期接口耗时
- 某个线程进入 WAITING 状态
- 出现死锁
可参考JVM发生OOM的 8 种原因、及解决办法、快速定位高占用Java进程(show-busy-java-threads)、我的java问题排查工具单、再一次生产 CPU 高负载排查实践
jvm 分析
# 反编译(查看编译器生成的字节码)
javap -c -v ClassName
# 查看某个进程内部线程占用情况分析
top -H -p PID
# pstack显示每个进程的栈跟踪
pstack PID
# 垃圾回收统计
jstat -gc PID
# 查看jstack信息
jstack PID
jstack PID | grep 1731c -A90
CPU 分析
CPU 繁忙:线程中有无限空循环、无阻塞、正则匹配或者单纯的计算;发生了频繁的 GC;多线程的上下文切换;JIT 编译
- 首先使用 top、vmstat、ps 等命令定位 CPU 使用率高的线程:
top -p [processId] -H。
top -c可将系统资源使用情况实时显示出来 (-c 参数可以完整显示命令),接着输入大写P将应用按照 CPU 使用率排序,第一个就是使用率最高的程序。
jstack [pid]打印繁忙进程的堆栈信息- 通过
printf %0x [processId]转换进程 id 为 16 进制,在堆栈信息中查找对应的堆栈信息。 jstat -gcutil [pid]查看 GC 的情况是否正常,是否 GC 引起了 CPU 飙高。
例如
jstat -gcutil pid 200 50表示:每隔 200ms 打印 50次
- 可在 JVM 加入
-XX:+PrintCompilation参数,查看是否是 JIT 编译引起了 CPU 飙高。 jmap -dump:live,format=b,file=dump.hprof pid可导出一份内存快照文件,使用MAT分析即可。
PS:线程的几种状态说明
NEW,未启动的。不会出现在Dump中。
RUNNABLE,在虚拟机内执行的。
BLOCKED,受阻塞并等待监视器锁。
WATING,无限期等待另一个线程执行特定操作。
TIMED_WATING,有时限的等待另一个线程的特定操作。
TERMINATED,已退出的。
内存 分析
内存使用不当:频繁 GC,响应缓慢;OOM,堆内存、永久代内存、本地线程内存
系统频繁 FullGC 大致有五种情况:
- 内存泄漏
- 请求处理变慢导致同时申请内存的线程太多
- metaspace 耗尽
- 常量池将堆区占满
- 堆外内存耗尽
- 堆外内存: JNI、Deflater/Inflater、DirectByteBuffer。通过 vmstat、top、pidstat 等查看 swap 和物理内存的消耗状况。通过 Google-preftools 来追踪 JNI、Deflater 这种调度的资源使用情况。
- 堆内存:创建的对象、全局集合、缓存、ClassLoader、多线程
- 查看 JVM 内存使用情况:
jmap -heap <pid>。 - 查看 JVM 存活的对象:
jmap -histo:live <pid>。 - 把 heap 里所有对象都 dump 下来,无论对象是否死活:
jmap -dump:format=b,file=xxx.hprof <pid>。 - 先做一次 Full GC 再 dump,只包含存活的对象信息:
jmap -dump:format=b,live,file=xxx.hprof <pid>。 - 使用 Eclipse MAT 或者 jhat 打开堆 dump 的文件,根据内存中的具体对象使用情况分析
- VJTools 中的 vjmap 可以分代打印出堆内存的对象实例占用信息。
- 可以使用
jvisualvm命令,运行可视化的JVM 监控工具(JDK1.6+)。 jconsole: Java Monitoring and Management Console,其实 jvisualvm 已包含 jconsole 功能。
- 查看 JVM 内存使用情况:
使用Eclipse Memory Analyzer Tool(MAT)分析线上故障(一) - 视图&功能篇
必备面试题:系统CPU飙高和GC频繁,如何排查?
一文学会Java死锁和CPU 100% 问题的排查技巧
系统运行缓慢,CPU 100%,以及Full GC次数过多问题的排查思路
JVM 发生 OOM 的 8 种原因、及解决办法
磁盘 IO 分析
IO 性能差,大量的随机读写,设备慢,文件太大。
iostat -xz l查看磁盘 IO 情况r/s, w/s, rkB/s, wkB/s等指标过大,可能会引起性能问题。await过大,可能是硬件设备遇到了瓶颈或者出现故障。一次 IO 操作一般超过20ms就说明磁盘压
力过大。avgqu-sz大于1,可能是硬件设备已经饱和。%util越大表示磁盘越繁忙,100% 表示已经饱和。- 通过使用
strace工具定位对文件 IO 的系统调用。
需要安装linux性能优化工具包:sysstat
yum install -y sysstat
网络 IO 分析
netstat -anpt查看网络连接状况。当TIME_WAIT或者CLOSE_WAIT连接过多时,会影响应
用的响应速度。前者需要优化内核参数,后者一般是代码Bug没有释放网络连接。- 使用
tcpdump来具体分析网络 IO 的数据。tcpdump出的文件直接打开是一堆二进制的数据,可
以使用Wireshark查看具体的连接以及其中数据的内容。tcpdump -i eth0 -w tmp.cap -tnn dst port 8080 sar -n DEV查看否吐率和否吐数据包数,判断是否超过两卡限制。
IO 分析 Tips
%iowait在 Linux 的计算为 CPU 空闲、并且有仍未完成的 IO 请求的时间占总时间的比例。%iowait升高并不一定代表 IO 设备有瓶颈。需要结合其他指标来判断,如await(IO 操作等待耗时)、svctm(IO 操作服务耗时)等。avgqu-sz是按照单位时间的平均值,所以不能反映瞬间的 IO 洪水。
CPU 使用优化
不要存在一直运行的线程(无限循环),可以使用 Sleep 休眠一段时间。这种情况带着存在于一些
pull 方式消费数据的场景下,当一次 pull 没有拿到数据的时候建议 sleep 一下,再做下一次 pull。- 轮询的时候可以使用
wait/notity机制代替循环。 避免正则表达式匹配、过多的计算。例如,避免使用String的format、split、replace方法; 避免免使用正则去判断邮箱格式(有时候会造成死循环);避免序列/反序列化。使用线程池,减少线程数以及线程的切换。- 多线程对于锁的竞争可以考虑
减小锁的拉度(使用Reetrantllock)、拆分锁(类似
ConcurrentHashMap 分 bucket 上锁),或者使用 CAS、ThreadLocal、不可变对象等无锁技术。此外,多线程代码的编写最好使用JDK提供的并发包、Executors框架以及ForkJoin等,此外外Disruptor和Actor在合适的场景也可以使用。 - 结合JVM和代码一起进行分析,
避免产生频繁的CC,尤英是Full GC。
内存使用优化
- 使用
基本数据类型而不是其包装类型能够节省内存。 尽量避免分配大对象。大对象分配的代价以及初始化的代价很大,不同大小的大对象可能导致 Java 堆碎片,尤其是 CMS;避免改变数据结构大小。如避免改变数组或orray backed collections/containers的大小;对象构建(初始化)时最好显式批量定教组大小;改变大小导致不必要的对象分配,可能导致 Java 堆碎片。- 避免保存重复的 String 对象,同时也需要小心 String.substringt() 和 String.intern() 的使用,中间过程会生成不少字符串。
- 尽量不要使用 finalizer。
释放不必要的引用:Threadlocal 使用完记得释放以防止内存泄露,各种 stream 使用完也记得
close。使用对象注池避免无节制创建对象,造成频繁 CC,但也不要随便使用对象池,除非像连接池、线程池这种初始化/创建资源消耗较大的场景。- 缓存失效算法,可以考虑使用 SoftReference、WeakReference 保存缓存对象。
- 谨慎热部署/加载的使用,尤其是动态加载类等。
- 打印日志时
不要输出文件名、行号,因为日志框架一般都是通过打印线程堆栈实现,生成大量 String。 此外,打印日志时,先判断对应级别的日志是否打开再做操作,否则也会生成大量 String。
CMS 垃圾回收部分参数调整(remark耗时过长)
remark如果耗时较长,通常原因是在 CMS GC 已经结束了concurrent-mark步骤后,旧生代的引用关系仍然发生了很多的变化,旧生代的引用关系发生变化的原因主要是:
1.在这个间隔时间段内,新生代晋升到旧生代的对象比较多;
2.在这个间隔时间段内,创建出来的对象又比较多,年轻带也是 CMS 的。
- a.增加了CMS回收的线程数:
-XX:ParallelGCThreads=N
-XX:ParallelCMSThreads=M
调整这2个参数都可以,它们的关系:ParallelCMSThreads = (ParallelGCThreads + 3)/4)
- b.开启并行
remark
-XX:+CMSParallelRemarkEnabled
- c.强制
remark之前开始一次Minor GC,从而减少remark阶段扫描年轻代gc root的开销
-XX:+CMSScavengeBeforeRemark
IO 使用优化
- 考虑使用异步写入代替同步写入,可以借鉴Redis的AOP机制。
- 利用预读取或者缓存,减少随机读。
- 尽量批量写入,减少 IO 次数和寻址。
- 使用数据库代替文件存储。
- 使用异步 IO /多路复用 IO /事件驱动 IO 代替同步阻塞 IO。
- 使用协程提高网络 IO 性能:Quasar。
JVM 配置
常用参数配置(参考公司ppt,粗略)
最大堆和初始堆
-Xmx、-Xms设置相等,减少程序运行时进行的垃圾回收次数,提高性能
新生代的配置
-Xmn一般新生代大小设置为整个堆的1/3-1/4
-XX:SurvivorRatio,设置eden区与survivor区比例
堆溢出处理
-XX:+HeapDumpOnOutOfMemoryError、-XX:HeapDumpPath
记录溢出发生现场的堆dump文件
- 合理设置各个代的大小。新生代尽量设置的大,但不能过大(会产生碎片),同样也要避免Survivor设置的过大和过小。
- 选择合适的 GC 策略。需要根据不同的场景选择合适的 GC 策略。CMS 并非全能的。除非特别需要再设置,毕竟 CMS 的新生代回收策略 ParNew 并非最快的,且会产生碎片。
- 老年代优先使用
Parallel GC (-XX:+UserParallel[Old]GC),可以保证最大的吞吐量。由于 CMS 会产生碎片,确实有必要才改成 CMS 或 G1。 - 注意内存强(严重阻碍处理器性能发挥的内存瓶颈),一般来讲单点应用对内存设置为4G到5G即可,依靠可扩展性提高并发能力。
- 设置 JVM 的内存大小有个经验法则:完成 Full GC 后,应该释放出来 ==70%== 的内存。
- 配置堆内存和永久代/元空间内存之和小于 32GB ,从而可以使用压缩指针节省对象指针的占用。
- 打开 GC 日志并读懂 GC 日志,以便于排查问题。GC的日志文件可以通过
GC Histogram (gchisto)生成图表和表格。 - G1 从 JDK9 开始,作为了默认垃圾收集器,既支持新生代又支持老年代(
-XX:+UseG1GC)
代码性能建议
- 算法、逻辑上是程序性能的首要,遇到性能问题,应该首先
优化程序的逻辑处理。 优先考虑使用返回值而不是异常表示错误。虽然现代 JVM 已经做了大量优化工作,但毕竟异常是有代价的,需要在合适的地方使用。一般用错误码返回值处理可能会发生的事情,用异常捕捉处理不期望发生的事情。如果使用异常并且比较关注性能,可以通过覆盖掉异常类的fillInStackTrace()方法为空方法,使其不拷贝栈信息。查看自己的代码是否对内联是友好的,内联友好指的方法的大小不超过 35 字节(默认的内联阈值,不建议修改)、非虚方法(虚方法指的是在运行期才能确定执行对象的方法,最新的 JVM 对非虚方法会通过 CHA 类层次分析来判断是否可以内联)。
协程
协程,英文 Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,例如:Kilim框架。
Spring AOP
- 如果被代理的目标对象实现了接口,那么Spring会默认使用JDK动态代理。所有该目标类型实现的接口都将被代理。若该目标对象没有实现任何接口,则创建一个CGLIB代理。
- 如果是被代理类的方法自调用,在自调用的过程中,是类自身的调用,而不是代理对象去调用,那么就不会产生 AOP,因为这样Spring就不能把你的代码织入到约定的流程中。
- 需要代理的对象方法不能是private的,因为Spring不管使用的是JDK动态代理还是CGLIB动态代理,一个是针对接口实现的类,一个是通过子类实现。无论是接口还是父类,显然都不能出现 private 方法,否则子类或实现类都不能覆盖到。如果方法为private,那么在代理过程中,根本找不到这个方法,引起代理对象创建出现问题,也就可能会导致有的对象没有注入成功。
- 只要是以代理方式实现的声明式事务,无论是JDK动态代理,还是CGLIB直接写字节码生成代理,都只有public方法上的事务注解才起作用。而且必须在代理类外部调用才行,如果直接在目标类里面调用,代理照样不起作用。
【JVM】12_空间分配担保
在发生
Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么Minor GC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次Minor GC,尽管这次Minor GC是有风险的;如果小于,或者HandlePromotionFailure设置不允许冒险,那这时也要改为进行一次Full GC。
取平均值进行比较其实仍然是一种动态概率的手段,也就是说,如果某次Minor GC存活后的对象突增,远远高于平均值的话,依然会导致担保失败(Handle Promotion Failure)。如果出现了HandlePromotionFailure失败,那就只好在失败后重新发起一次Full GC。虽然担保失败时绕的圈子是最大的,但大部分情况下都还是会将HandlePromotionFailure开关打开,避免Full GC过于频繁。
JDK 6.0.24以后就认为HandlePromotionFailure一直是true(只有定义,未使用)。
漫画说算法--动态规划算法三
三个核心元素:最优子结构、边界、状态转移方程式。
1.问题建模 -- 状态转移方程
2.问题求解
爬楼梯问题:
- 递归时间复杂度太高 O(2^N)
- 备忘录算法(暂存计算结果)时间复杂度:O(N) 空间复杂度:O(N) (自顶向下计算)
- 动态规划求解 时间复杂度:O(N) 空间复杂度:O(1) (自底向上计算,不需要保留全部临时结果)
国王和金矿问题:
当金矿只有5座的时候,动态规划的性能优势还没有体现出来。当金矿有10座,甚至更多的时候,动态规划就明显具备了优势。
由于动态规划的时间和空间复杂度都和工人数量成正比,而简单递归却和工人数量无关,所以当工人数量很多时,动态规划算法反而不如递归。
3.
RocketMQ
RocketMQ 无法避免消息重复,如果业务对消费重复非常敏感【需要消费过程要做到幂等(即消费端去重)】
总结在多线程中几种释放锁和不释放锁的操作
不释放锁
- 线程执行同步代码块或同步方法时,程序调用Thread.sleep(Long l)、Thread.yield()方法暂停当前线程的执行
- 线程执行同步代码块时,其它线程调用该线程suspend()方法将该线程挂起,该线程不会释放锁(同步监视器)
- 尽量避免使用suspend()和resume()来控制线程
释放锁
- 当前线程的同步方法、同步代码块执行结束
- 当前线程的同步方法、同步代码块遇到break、return终止该代码块、该方法的继续执行
- 当前线程的同步方法、同步代码块中出现了未处理Error和Exception,导致异常结束
- 当前线程在同步方法、同步代码块中执行了线程对象的wait()方法,当前线程暂停,并释放锁
Log4j NDC MDC 区别及用法
NDC(Nested Diagnostic Context)和MDC(Mapped Diagnostic Context)是log4j中非常有用的两个类,它们用于存储应用程序的上下文信息(context infomation),从而便于在log中使用这些上下文信息。
NDC
采用了一个类似栈的机制来push和pop上下文信息,每一个==线程都独立==地储存上下文信息。比如说一个servlet就可以针对每一个request创建对应的NDC,储存客户端地址等等信息。
当使用的时候,我们要尽可能确保在进入一个context的时候,把相关的信息使用NDC.push(message);在离开这个context的时候使用NDC.pop()将信息删除。另外由于设计上的一些问题,还需要保证在当前thread结束的时候使用NDC.remove()清除内存,否则会产生内存泄漏的问题。
存储了上下文信息之后,我们就可以在log的时候将信息输出。在相应的PatternLayout中使用”%x”来输出存储的上下文信息,下面是一个PatternLayout的例子:
log4j.appender.console.layout.ConversionPattern=%-d{yyyy/MM/dd HH:mm:ss,SSS} [%X] -[%c]-[%p] %m%n
使用NDC最重要的好处就是,当我们想输出一些上下文的信息的时候,不需要让logger去寻找这些信息,而只需要在适当的位置进行存储,然后再配置文件中修改PatternLayout。在最新的log4j 1.3版本中增加了一个org.apache.log4j.filters.NDCMatchFilter,用来根据NDC中存储的信息接受或拒绝一条log信息。
MDC
MDC和NDC非常相似,所不同的是MDC内部使用了类似map的机制来存储信息,上下文信息也是每个==线程独立==地储存,所不同的是信息都是以它们的key值存储在”map”中。相对应的方法,MDC.put(key, value); MDC.remove(key); MDC.get(key);
在配置PatternLayout的时候使用:%x来输出对应的value。
log4j.appender.console.layout.ConversionPattern=%-d{yyyy/MM/dd HH:mm:ss,SSS} [%X{ip}] -[%c]-[%p] %m%n
如果在项目中有过滤器,你可以把获取ip 的方法直接定义在过滤器中,然后在配置文件中配置获取ip的显示就可以了。
同样地,MDC也有一个org.apache.log4j.filters.MDCMatchFilter。这里需要注意的一点,MDC是线程独立的,但是一个子线程会自动获得一个父线程MDC的copy。
至于选择NDC还是MDC要看需要存储的上下文信息是堆栈式的还是key/value形式的。
Java对BIO、NIO、AIO的支持:
- Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
- Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
- Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
BIO、NIO、AIO适用场景分析:
- BIO:方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
- NIO:方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
- AIO:方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
一般来说I/O模型可以分为:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞IO
- 同步阻塞IO:在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,用户进程才能运行。JAVA传统的IO模型属于此种方式!
- 同步非阻塞IO:在此种方式下,用户进程发起一个IO操作以后边可返回做其它事情,但是用户进程需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。其中目前JAVA的NIO就属于同步非阻塞IO。
- 异步阻塞IO:此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄,从而提高系统的并发性!
- 异步非阻塞IO:在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。目前Java中还没有支持此种IO模型。
阻塞/非阻塞:描述的是调用者调用方法后的状态,比如:线程A调用了B方法,A线程处于阻塞状态。
同步/异步:描述的方法跟调用者间通信的方式,如果不需要调用者主动等待,调用者调用后立即返回,然后方法本身通过回调,消息通知等方式通知调用者结果,就是异步的。如果调用方法后一直需要调用者一直等待方法返回结果,那么就是同步的。
java中右移运算符 >> 和无符号右移运算符 >>> 的区别
- 左移<< :就是该数对应二进制码整体左移,左边超出的部分舍弃,右边补零。
举个例子:253的二进制码1111 1101,在经过运算253<<2后得到1111 0100。很简单
- 右移>> :该数对应的二进制码整体右移,左边的用原有标志位补充(正数补0负数补1),右边超出的部分舍弃。
- 无符号右移>>> :不管正负标志位为0还是1,将该数的二进制码整体右移,左边部分总是以0填充,右边部分舍弃。
因为左移始终是在右边补,不会产生符号问题,所以没有必要存在 无符号左移 <<<(Java中也不存在)。
举例对比:
-5 用二进制表示 1111 1011,加粗为该数标志位
-5 >> 2 : 1111 1011 --------------> ==11==11 1110。
==11==为标志位补充的
-5 >>> 2 : 1111 1011--------------> ==00==11 1110。
==00==为补充的0
负数的二进制表示
为什么-x=!x+1???
其中x为一任意int型正整数,左式表示取x的相反数后的二进制形式,右式表示先将x的二进制按位取反后再加一得到的二进制形式。
假设有一个 int 类型的数,值为5,那么,我们知道它在计算机中表示为:
00000000 00000000 00000000 00000101
5转换成二制是101,不过int类型的数占用4字节(32位),所以前面填了一堆0。
现在想知道,-5在计算机中如何表示?
在计算机中,负数以原码的补码形式表达。
什么叫补码呢?这得从原码,反码说起。
原码:
一个正数,按照绝对值大小转换成的二进制数;一个负数按照绝对值大小转换成的二进制数,然后最高位补1,称为原码。
比如:
00000000 00000000 00000000 00000101 是 5的 原码。
10000000 00000000 00000000 00000101 是 -5的 原码。
反码:
**正数的反码与原码相同,负数的反码为对该数的原码除符号位外各位取反。 **
取反操作指:原为1,得0;原为0,得1。(1变0; 0变1)
比如:
正数 00000000 00000000 00000000 00000101 的反码
还是 00000000 00000000 00000000 00000101
负数 10000000 00000000 00000000 00000101 每一位取反(除符号位),
得到 11111111 11111111 11111111 11111010。
称:
11111111 11111111 11111111 11111010 是
10000000 00000000 00000000 00000101 的反码。
反码是相互的,所以也可称:
10000000 00000000 00000000 00000101 和
11111111 11111111 11111111 11111010 互为反码。
补码:
**正数的补码与原码相同,负数的补码为对该数的原码除符号位外各位取反,然后在最后一位加1. **
比如:
10000000 00000000 00000000 00000101 的反码是:
11111111 11111111 11111111 11111010。
那么,补码为:
11111111 11111111 11111111 11111010 + 1 =
11111111 11111111 11111111 11111011
所以,-5 在计算机中表达为:11111111 11111111 11111111 11111011。转换为十六进制:0xFFFFFFFB。
再举一例,我们来看整数-1在计算机中如何表示。 假设这也是一个int类型,那么:
1、先取原码:10000000 00000000 00000000 00000001
2、得反码: 11111111 11111111 11111111 11111110(除符号位按位取反)
3、得补码: 11111111 11111111 11111111 11111111
可见,-1在计算机里用二进制表达就是全1。16进制为:0xFFFFFF
正零和负零的补码相同
[+0]原码=0000 0000, [-0]原码=1000 0000
[+0]反码=0000 0000, [-0]反码=1111 1111
[+0]补码=0000 0000, [-0]补码=0000 0000
再看看这个规律表
原码 补码 值
0111 1111 0111 1111 +127
0111 1110 0111 1110 +126
... .. 补码不断-1...
0000 0000 0000 0000 0
1000 0001 1111 1111 -1
1000 0010 1111 1110 -2
1000 0011 1111 1101 -3
... . 补码不断-1...
1111 1111 1000 0001 -127
无法表达 1000 0000 -128
于是就有了规定 1000 0000 定为 -128的补码,这种定法和数学层面的表述是一致的。
评论区