


1.计算机基础
1.1 TCP/IP 网络协议(从上自下)
程序在发送消息时,
- 应用层(HTTP/FTP/SMTP/TELNET..):按照既定协议打包
- 传输层(TCP/UDP):加上双方的端口号
- 网络层(IP/ARP):加上双方的 IP 地址
- 链路层(IEEE 802.x/PPP..):加上双方的 MAC 地址,并将数据拆分成数据帧,经过多个路由器和网关后,到达目标机器。
简而言之,就是按照**"端口 -> IP 地址 -> 地址"**这样的路径进行数据的封装和发送,解包的时候反过来操作即可。
1.2 信息安全 CIA 原则
互联网企业都要建立一套完整的信息安全体系,遵循 CIA 原则,即保密性(Confidentiality)、完整性(Integrity)、可用性(Availability)。
2.面向对象
2.1 类
在定义 Java 类时,推荐首先定义变量,然后定义方法。公有方法是使用者和维护者最关心的,最好首屏展示;保护方法重要性仅次于共有方法;私有方法相当于黑盒实现,一般不要被特别关注;最后是 getter/setter 方法,虽然是公有的,但承载的信息价值较低,一般不包含业务逻辑,所以都放到类最后。
抽象类在被继承时体现的是:is-a 关系(需要符里氏代换原则),模板式设计;
接口在被实现时体现的是:can-do 关系(需要符合接口隔离原则),契约式设计。
2.1.1 访问权限控制
定义类时,访问控制级别要从严处理(推荐最小化),只把有限的方法和成员公开给别人(迪米特法则——最少知识原则的内在要求)。
- 1.如果不允许外部直接通过 new 创建对象,构造方法必须是
private。 - 2.工具类不允许有
public或default构造方法。 - 3.类非
static成员变量并且与子类共享,必须是protected。 - 4.类非
static成员变量并且仅在本类使用,必须是private。 - 5.类
static成员变量如果仅在本类使用,必须是private。 - 6.若是
static成员变量,必须考虑是否为final。 - 7.类成员方法只供类内部调用,必须是
private。 - 8.类成员方法只对继承类公开,那么限制为
protected。
2.1.2 类关系
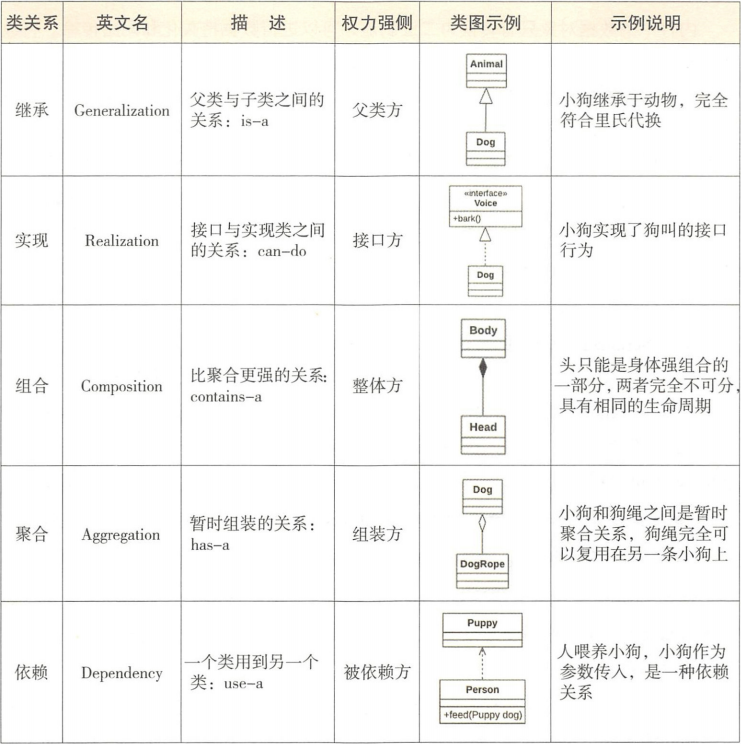
类关系包含如下 5 种类型:
- [ 继承 ] extends (is-a)
- [ 实现 ] implements (can-do)
- [ 组合 ] 类是成员变量 (contains-a)
- [ 聚合 ] 类是成员变量 (has-a)
- [ 依赖 ] import 类 (use-a)
注意组合和聚合的区别,组合:是一种完全绑定的关系,所有成员共同完成一件使命,他们的生命周期是一样的,体现的是非常强的整体与部分的关系,==同生共死==,部分不能在整体之间共享;
聚合:是一种可拆分的整体与部分的关系,是非常松散的==暂时组合==,部分可以被拆出来给另一个整体。
在 UML 类图中,空心三角形△表示继承,实心菱形◆表示组合,空心菱形◇表示聚合,这三者都是实线连接。
用空心三角形△来表示实现(接口),用一个箭头↑表示依赖,虚线连接。
有一个规律:有形状的图形符号一律放在权利强的一侧。
==序列化==并不保存静态变量。
2.2 重写
方法覆写的口诀:
- 一大: 访问权限控制符只能更大(或相同)
- 二小: 返回值和抛出异常只能更小(或相同)
- 二相同:方法名和参数列表须相同(方法签名)
重写是在运行期间由JVM进行绑定,调用合适覆写方法来执行。
重载是编译器确定方法调用,属于静态绑定。
2.3 泛型
- 1.尖括号
<>里的每个元素都指代一种未知类型。
即使 String 出现在尖括号里,它也不是 java.lang.String了 ,而仅仅是一个代号。
类名后方定义的泛型<T>和方法返回值前方定义的<T>是两个指代,可以完全不同,互不影响。
- 2.尖括号的为位置非常讲究,必须在类名之后或者方法返回值之前。
- 3.泛型在定义处只具备执行 Object 方法的能力。
在定义了泛型的方法内部,泛型只能调用 Object 类中的方法,如 toString()。
- 4.对于编译之后的字节码指令,其实没有这些花头花脑的方法签名,充分说明了泛型只是一种编写代码时的语法检查。
在使用泛型元素肘,会执行强制类型转换。(存在类型擦除)
使用泛型的好处:
- 类型安全:放置的是什么,取出来自然是什么,不用担心会抛出 ClassCaseException 异常。
- 提升可读性:从编码阶段就显式的知道泛型集合、泛型方法等处理的对象类型是什么。
- 代码重用:泛型合并了同类型的处理代码,使代码重用度变高。
2.4 数据类型
基本数据类型
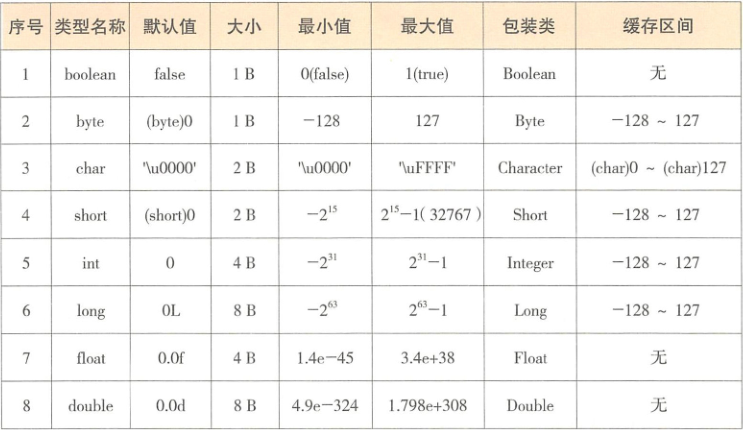
对象的存储空间分配单位是8个字节(必须是 8B 的倍数)。
包装类型和基本数据类型的选择:
-
- 全部的POJO类属性必须使用包装数据类型。
-
- RPC 方法的返回值和参数必须使用包装数据类型。
-
- 所有的局部变量推荐使用基本数据类型。
-
- 在定义POJO中的布尔类型的变量时,不要使用
isSuccess这种形式,而要直接使用success。
- 在定义POJO中的布尔类型的变量时,不要使用
POJO类的布尔类型属性要使用基本数据类型,不使用包装数据类型(这一条非阿里规范,有待再确认)可参考:为什么阿里巴巴禁止开发人员使用isSuccess作为变量名?
3.代码风格
3.1 命名规约
命名要符合语言特性、体现元素特征。命名做到望文知义、自解释是每个开发工程师的基本素质之一。
推荐命名时能体现元素特征:
- 包名统使用小写,点分隔符之间有且仅有1个自然语义的英语单词。
- 包名统一使用单数形式,但是类名如果有复数含义,则可以使用复数形式。
- 抽象类命名使用
Abstract或Base开头;异常类命名使用Exception结尾,测试类命名以它要测试的类名开始,以Test结尾。 - 类型与中括号紧挨相连来定义数组。
- 枚举类名带上
Enum后缀,枚举成员名称需要全大写,单词间用下画线隔开。
变量起名可参考:CODELF
3.1.1 常量
-
状态(没有扩展信息的)可以用 不能实例化的抽象类的全局常量来表示。
-
类型(有扩展信息的)可以用 枚举类型来表示全局常量,并描述扩展信息。
-
魔法值“害人害己”,无论如何都不允许任何魔法值直接出现在代码中(常在河边走哪有不湿鞋)。
-
某些公认的字面常量是不需要预先定义的,但如果具备了特殊含义,就必须定义出有意义的常量名称。
必须:for() 里的 0 可以直接使用,true 和 false 可以直接使用。
-
类内常量必须全部大写,单词间用下划线隔开,力求语义表达完整清楚(不要嫌长);方法内常量使用小驼峰即可。
3.1.1 变量
一般情况下,变量的命名需要满足小驼峰格式,命名体现业务含义即可。
存在一种特殊情况,在定义类成员变量时,特别是在 POJO 类中,针对布尔类型的变量,命名不要加
is前缀,否则部分框架解析会引起序列化错误,但是数据库建表中,推荐表达是与否的字段采用is_xxx的命名方式(需要配置POJO映射)。
3.2 代码展示风格
3.2.1 缩进、空格和换行
- 推荐使用4个空格代表缩进,禁止使用 Tab(不同编辑器对Tab解析不一致)
- 空格用于分隔不同的编程元素,可以让运算符、数值、注释、参数等各种编程元素错落有致,方便快速定位。
- 空行用来分隔功能相似、逻辑内聚、意思相近的代码片段,是得程序布局更加清晰。浏览时也能起到自然停顿的作用,提升阅读体验。
例如在:方法定义之后、属性定义和方法定义之间、不同逻辑、不同语义、不同业务的代码之间都需要通过空行来分隔。
3.2.2 换行和高度
- 代码中需要限定每行的字符个数,以便适配显示器的宽度,以及方便CodeReview时进行diff对比,要求单行字符数不超过 120 个,超出则需换行。
- 应该将次要逻辑抽取为独立方法,将共性逻辑抽取为共性方法(比如参数校验、权限判断等),便于复用和维护,使主干代码逻辑更加清晰。
- 约定单个方法总行数不超过 80 行(除注释之外,方法签名、左右大括号、方法内代码、空行、回车及任何不可见字符的总行数不超过 80 行)。
心理学认为人对事物的印象通常不能超过 3 这个魔法数,三屏是人类短期记忆的极限,而 80 行在一般显示器上是两屏半的代码量。
3.2.3 控制语句
-
在
if、else、for、while等语句中必须使用大括号,即使只有一行代码。 -
在条件表达式中不允许有赋值操作,也不允许在判断表达式中出现复杂的逻辑组合。
可以将复杂的逻辑运算赋值给一个具有业务含义的布尔变量。
-
多层嵌套不能超过 3 层,如果非得使用多层嵌套,请使用设计模式。
对于超过 3 层的if-else逻辑判断可以使用卫语句、策略模式、状态模式等来实现。
-
避免采用取反逻辑运算符。
3.3 代码注释
3.3.1 优雅注释三要素
- 1.Nothing is strange
我们提倡要写注释,然后才是把注释写的精简。
- 2.Less is more
代码中的注释一定是精华中的精华。
- 3.Advance with the times
任何对代码的修改,都应该同时修改注释。
3.3.2 注释格式
- 1.Javadoc 规范
类、类属性和类方法的注释必须遵循 Javadoc 规范,使用文档注释(/** */)的格式。
按 Javadoc 规范编写的注释,可以生成规范的 JavaAPI 文档,为外部用户提供非常有效的文档支持。
而且在使用 IDE 工具编码时,IDE 会自动提示所用到的类、方法等注释,提高了编码的效率。
对于枚举类型的注释是必需的:
1)==枚举类型实在太特殊了,它的代码极其稳定==。如果它的定义和使用出现错误,通常影响较大。
2)==注释的内容不仅限于解释属性值的含义,还可以包括注意事项、业务逻辑==。如果在原有枚举类上新增或修改一个属性值,还需要加上创建和修改时间,让使用者零成本地知道这个枚举类的所有意图。
3)==枚举类的删除或者修改都存在很大的风险==。不可直接删除过时属性,需要标注为过时,同时注释说明过时的逻辑考虑和业务背景。
- 2.简单注释
包括单行注释和多行注释。
特别强调此类注释不允许写在代码后方,必须写在代码上方,这是为了避免注释的参差不齐,导致代码版式混乱。
双画线注释往往使用在方法内部,此时的注释是提供给程序开发者、维护者和关注方法细节的调用者查看的。
因此,注释的作用更应该是画龙点睛的,通常添加在非常必要的地方,例如复杂算法或需要警示的特殊业务场景等。
4.走进 JVM
4.1 字节码
静态编译器转到源码成字节码的过程:
字节码必须通过类加载过程加载到 JVM 环境后,才可以执行。
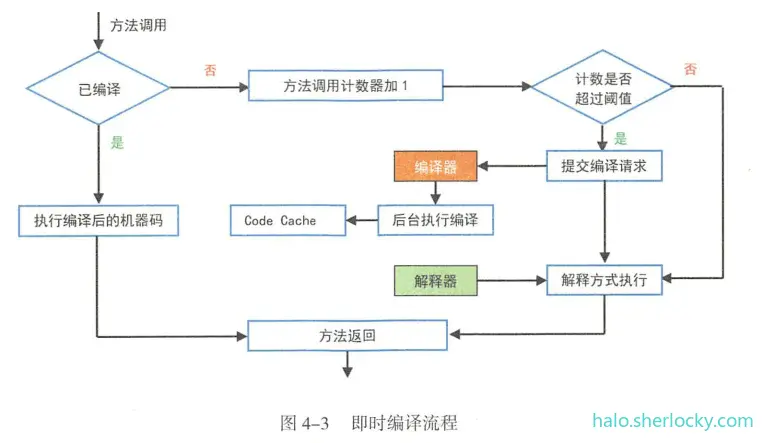
执行有三种模式,第1.解释执行;第2.JIT 编译执行;第3.JIT 编译与解释混合执行(主流 JVM默认执行模式)。
混合执行模式的优势在于解释器在启动时先解释执行,省去编译时间。随着时间推进,JVM 通过热点代码统计分析,识别高频的方法调用、循环体、公共模块等,基于强大的 JlT 动态编译技术,将热点代码转换成机器码,直接交给 CPU 执行。
JIT 的作用是将 Java 字节码动态地编译成可以直接发送给处理器指令执行的机器码。
JIT 即时编译流程图:
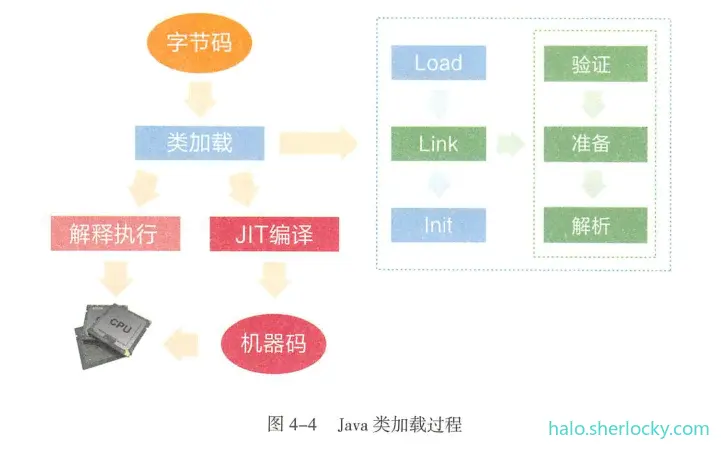
4.2 类加载过程
类加载过程图:
类加载是一个将
.class字节码文件实例化成Class对象,并进行相关初始化的过程。
内存布局、垃圾回收等内容直接阅读原书比较好。
依赖倒置原则主要规定了两件事情:
- 高层模块不应该依赖底层模块,两者都应该依赖抽象
- 抽象不应该依赖细节,细节应该依赖抽象。
JSR(Java Specification Request)规范的内容都是抽象的,其对外发布的形式都是接口,它不提供实现,最多会指导实现。
5.异常与日志
处理程序异常,需要解决以下 3 个问题:
- (1)哪里发生异常?
- (2)谁来处理异常?
- (3)如何处理异常?
不论是哪种方式处理异常,都严禁捕获异常后什么都不做或打印一行日志了事。
如果在方法内部处理异常,需要根据不同业务场景进行定制处理,如重试、回滚等操作。
如果向上抛出异常,需要在异常对象中添加上下文参数、局部变量、运行环境等信息,这样有利于排查问题。
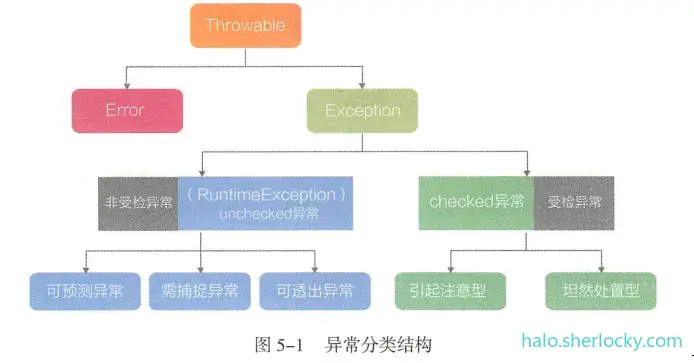
5.1 异常分类
5.2 try 代码块
如果finally代码块没有执行,那么有三种可能:
- 没有进入
try代码块。 - 进入
try代码块,但是代码运行中出现了死循环或死锁状态。 - 进入
try代码块,但是执行了System.exit()操作。
注意,
finally是在return表达式运行后执行的,此时将要return的结果已经被暂存起来,待finally代码块执行结束后再将之前暂存的结果返回(即使在finally中修改了返回值,也是无效的)。
finally代码块中使用return语旬,使返回值的判断变得复杂,所以避免返回值不可控,我们不要在finally代码块中使用return语句。
Lock 、ThreadLocal、InputStream等这些需要进行强制释放和清除的对象都得在finally代码块中进行显式的清理,避免产生内存泄漏,或者资源消耗。
所以在
try代码块之前调用lock()方法,避免由于加锁失败导致finally调用unlock()抛出异常。
5.3 异常的抛与接
传递异常信息的方式是通过抛出异常对象,还是把异常信息转成信号量封装在特定对象中,这需要方法提供者和方法调用者之间达成契约,只有大家都照章办事,才不会产出误解。
- 推荐对外提供的开放接口使用错误码;
- 公司内部跨应用远程服务调用优先考虑使用
Result对象来封装错误码、错误描述信息; - 而应用内部则推荐直接抛出异常对象。
关于NPE问题,契约式编程理念就完全处于防御式编程理念的下风,所以我们推荐方法的返回值可以为null,不强制返回空集合或者空对象等,但是必须添加注释充分说明什么情况下会返回null值。防止NPE一定是调用方的责任,需要调用方进行事先判断。
5.4 日志
记录应用系统曰志主要有三个原因:记录操作轨迹、监控系统运行状况、回溯系统故障。
5.4.1 日志规范
- 1.预先判断日志级别
- 2.避免无效日志打印
生产环境禁止输出 DEBUG 曰志旦有选择地输出 INFO 日志。
使用 INFO、WARN 级别来记录业务行为信息时,一定要控制日志输出量,以免磁盘空间不足。同时要为曰志文件设置合理的生命周期,及时清理过期的日志。避免重复打印,务必在日志配置文件中设置additivity=false。 - 3.区别对待错误日志
WARN、ERROR 都是与错误有关的日志级别,但不要一发生错误就笼统地输出ERROR 级别日志。一些业务异常是可以通过引导重试就能恢复正常的,例如用户输入参数错误。在这种情况下,记录日志是为了在用户咨询时可以还原现场,如果输出为 ERROR 级别就表示一旦出现就需要人为介入,这显然不合理。所以,ERROR 级别只记录系统逻辑错误、异常或者违反重要的业务规则,其他错误都可以归为 WARN级别 。
- 4.保证记录内容完整
日志是一个系统必不可少的组成部分,但日志打印并非多多益善,过多的日志会降低系统性能,也不利于快速定位问题,所以记录曰志时一定请思考三个问题:
①.日志是否有人看;②.看到这条日志能做什么;③.能不能提升问题排查效率。
5.4.2 日志框架
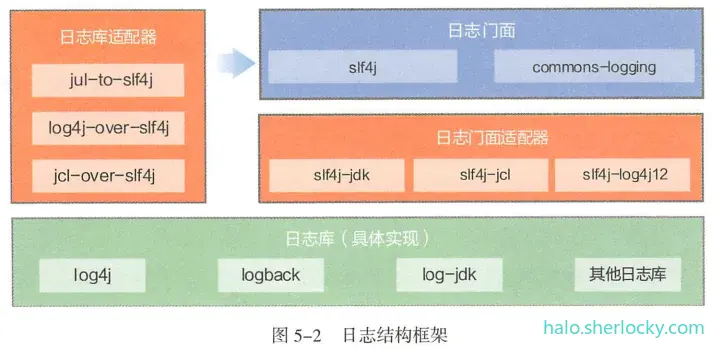
推荐logge被定义为private static final的:
private static final Logger logger= LoggerFactory.getLogger(Abc . class);
注意,
logger被定义为static变量,是因为这个logger与当前类绑定,避免每次都new一个新对象,造成资源浪费,甚至引发OutOfMernoryError问题。
在使用slf4j+日志库模式时,要防止日志库冲突,一旦发生则可能会出现
日志打印功能失效的问题。
6.数据结构和集合
我们经常说,程序 = 数据结构 + 算法。
集合作为数据结构的载体,可对元素进行加工和输出,以一定的算法实现最基本的增删改查功能,因此集合是所有编程语言的基础。
6.1 数据结构
数据结构分类:线性结构、树结构、图结构、哈希结构。
6.2 集合框架图
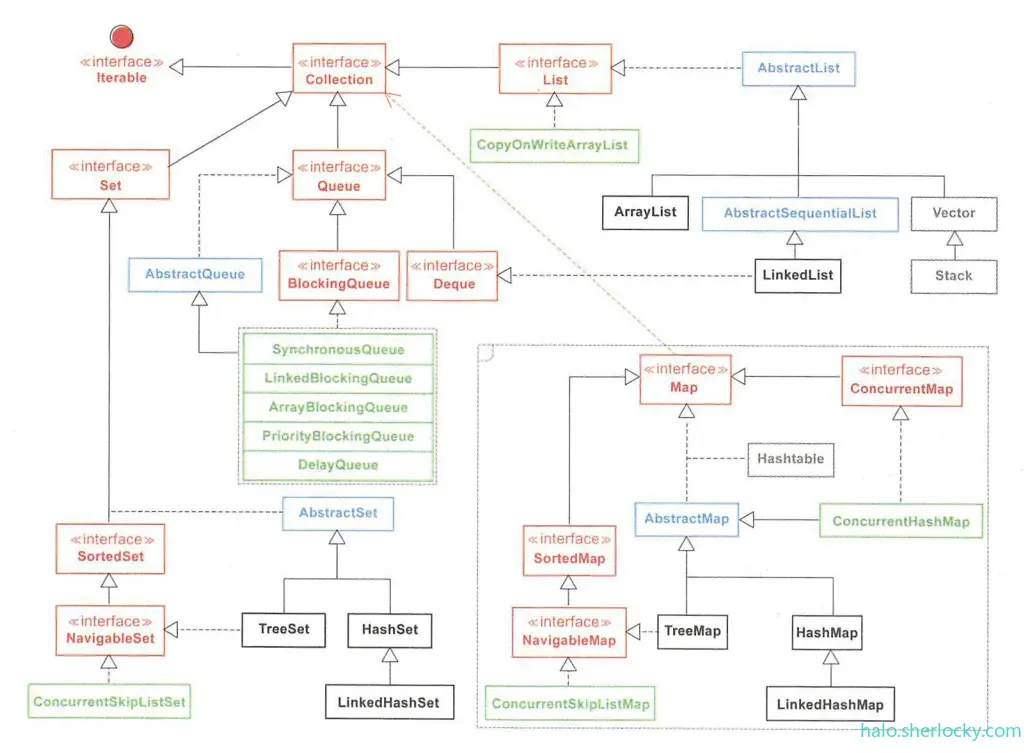
在集合框架图中,红色代表接口,蓝色代表抽象类,绿色代表并发包中的类,灰色代表早期线程安全的类(基本已经弃用)。
可以看到,与Collection相关的 4 条线分别是List、Queue、Set、Map,它们的子类会映射到数据结构中的表、树、哈希等。
6.3 集合初始化
集合初始化时,指定集合初始值大小。如果暂时无法确定集合大小,那么指定相应的默认值,这也要求我们记得各种集合的默认值大小,ArrayList大小为10,而HashMap默认值为16。
牢记每种数据结构的默认值和初始化逻辑,也是开发工程师基本素质的体现。
6.4 数组与集合
数组和集合的相互转换。
6.4.1 数组转集合
Arrays.asList体现的是适配器模式,返回对象是一个Arrays的内部类。
后台的数据仍是原有数组,可以通过set()方法修改元素的值(间接对数组进行值的修改操作),原有数组相应位置的值同时也会被修改。
但是不能进行修改元素个数的任何操作(内部类并没有实现集合个数的相关修改方法),否则均会抛出UnsupportedOperationException异常。
6.4.2 集合转数组
相对于数组转集合来说,集合转数组更加可控,毕竟是从相对自由的集合容器转为更加苛刻的数组。
- 1.不要用
toArray()无参方法把集合转换成数组,这样会导致泛型丢失。
List<String> list = new ArrayList<String>(3);
list.add("one");
list.add("two");
list.add("three");
// 泛型丢失,无法使用Sting[]接收无参方法返回的结果
Object[] arrayl = list.toArray();
- 2.即将复制进去的数组容量不足够的情况
会判断即将复制进去的数组容量是否足够。
如果容量不够,则弃用此数组,另起炉灶。
// 注意入参数组的 length 大小是重中之重,如果大于或等于集合的大小
// 则集合中的数据复制进入数组即可,如果空间不够,入参数组会被无视
// 重新分配一个空间,复制完成后返回一个新的数组引用
// array2 数组长度小于元素个数
String[] array2 = new String[2];
list.toArray(array2);
System.out.println(Arrays.asList(array2));
// 会打印:[null, null]
- 3.即将复制进去的数组容量足够的情况
// array3 数组长度等于元素个数
String[] array3 = new String[3];
list.toArray(array3 );
System.out.println(Arrays.asList(array3));
// 会打印:[one, two, three]
多次运行测试显示:当数组容量等于集合大小时,转换运行总是最快的,空间消耗也是最少的。
由此证明,如果数组初始大小设置不当,不仅会降低性能,还会浪费空间。使用集合的toArray(T[] array)方法,转换为数组时,注意需要传入类型完全一样的数组,并且它的容量大小为list.size()。
数组是协变的,而集合不是。
6.5 集合与泛型
泛型与集合的联合使用,可以把泛型的功能发挥到极致,很多程序员不清楚List、List<Object>、List<?>三者的区别,更加不能区分<? extends T>与<? super T>的使用场景。
List完全没有类型限制和赋值限定,如果天马行空地乱用,迟早会遭遇类型转换失败的异常。很多程序员觉得List<Object>的用法完全等同于List,但在接受其他泛型赋值时会编译出错。
List<?>是一个泛型,在没有赋值之前,表示它可以接受任何类型的集合赋值,赋值之后就不能随便往里添加元素了。
实现了List的集合类,是非泛型集合,可以赋值给任何泛型限制的集合。编译可以通过,但在运行时可能就会报错。在JDK5之后,应尽量使用泛型定义,以及使用类、集合、参数等。
List<Object>赋值给List<Integer>是不允许的,若是反过来赋值,依然会编译出错,提示如下:
Error:(x, y) java: incompatible types: java.util.List<java.lang.lnteger> cannot be converted to
java.utiI.List<java.lang.Object>
注意,数组可以这样赋值,因为它是协变的,而集合不是。
问号在正则表达式中可以匹配任何字符,List<?>称为通配符集合。
它可以接受任何类型的集合引用赋值,不能添加任何元素,但可以remove和clear,并非 immutable 集合。
List<?>一般作为参数来接收外部的集合,或者返回一个不知道具体元素类型的集合。
List<T>最大的问题是只能放置一种类型,如果随意转换类型的话,就是“破窗理论”,JDK 的开发者顺应了民意,实现了<? extends T>与<? super T>两种语法,但是两者的区别非常微妙。
<? extends T>是Get First,适用于消费集合元素为主的场景;<? super T>是Put First,适用于生产集合元素为主的场景。<? extends T>可以赋值给任何T及T子类的集合,上界为T,取出来的类型带有泛型限制,向上强制转型为T。null可以表示任何类型,所以除null外,任何元素都不得添加进<? extends T>集合内。<? super T>可以赋值给任何T及T的父类集合,下界为T。List<? super T>可以往里增加元素,但只能添加T自身及子类对象。extends的场景是put功能受限,而super的场景是get功能受限。- 所有的
super操作能返回元素,但是泛型丢失,只能返回Object对象。 List<? extends T>可以返回带类型的元素,但只能返回T自身及其父类对象,因为子类类型被擦除了。
6.6 元素的比较
。。。
评论区